Machine Learning como uma Função Serverless no Google Cloud Platform
Publicado em dom 10 maio 2020 na categoria tutorial • 13 min read
Introdução
Esse mês nos meus estudos de engenharia de machine learning tropecei em um tópico bem interessante: **machine learning como funções serverless**. Então, como se já não bastasse trabalhar umas 12 horas por dia (é sério), decidi construir uma pipeline BEM simples para o desenvolvimento de um modelo de regressão BEM básico e, em seguida, fazer o deploy deste modelo como uma função serveless na Google Cloud Platform. O resultado foi uma experiência bem interessante que me deu algum know how e um vislumbre de como poderia fazer o deploy de algo assim em produção com um sistema de maior escala. Talvez algum dia eu faça algo mais complexo envolvendo mais peças desse quebra cabeças.
Como sempre, espero que esse post possa dar uma luz para alguém fazendo algo parecido.
TL;DR: criei um modelo de machine learning e fiz o deploy como uma função serverless no GCP.
Objetivos do Post:
Suponhamos que você queira colocar seu apartamento para alugar, mas não sabe exatamente qual preço colocar no aluguel. Para isso você começa a procurar na internet por apartamentos mais ou menos igual ao seu na sua cidade e tenta tirar a média para gerar seu próprio valor de aluguel, cansativo, não?
Ia ser bem legal ter um modelo para tentar predizer o valor ideal para seu imóvel baseado em outros imóveis, né? Bem, é isso que vamos tentar fazer neste post.
- Desenvolvimento de um modelo para predição de valor de aluguel baseado em características do apartamento;
- Salvar o modelo treinado no Google Cloud Storage;
- Deploy do modelo treinado no Google Cloud Functions;
- Teste de funcionamento.
O que é uma Arquitetura Serverless?
Nos últimos anos, muito hype vem sendo criado em cima de arquiteturas serverless. Boa parte desse barulho é gerado por fornecedores de tais arquiteturas, onde principais são, obviamente: Google, Amazon e Microsoft, que investiram uma quantidade considerável de dinheiro nas suas plataformas serverless.
Ok, mas o que é uma arquitetura ou aplicação serverless? De acordo com o Martin Fowler, podemos dividir arquiteturas serverless em dois tipos: as BaaS (Backend as a Service) e as FaaS (Function as a Service). Em ambos os modelos, a parte de gerenciamento e arquitetura "server side" é toda tratada pelo provedor da plataforma, tirando essa responsabilidade do cliente. Arquiteturas serverless se beneficiam de uma redução de custo operacional, complexidade e necessidade de horas de engenharia. Para empresas com times reduzidos ou cientistas de dados ao estilo "faz tudo", esse tipo de aplicação é de grande ajuda, já que boa parte do processo de deploy é abstraída pelo provedor do serviço.
Para este post, vamos focar em aplicações FaaS. Neste tipo de aplicação, simplesmente criaremos uma função principal (main method) e usaremos as máquinas do Google Cloud Platform para hospedá-la. Essa função pode ser escrita em diferentes linguagens, obviamente utilizei Python3. Uma vez que a função tenha sido criada, sua execução será feita mediante requisições externas, ou seja, on demand. A parte de escalabilidade e distribuição também fica por conta do google, o que é uma mão na roda e tanto.
Pipeline do Mini Projeto
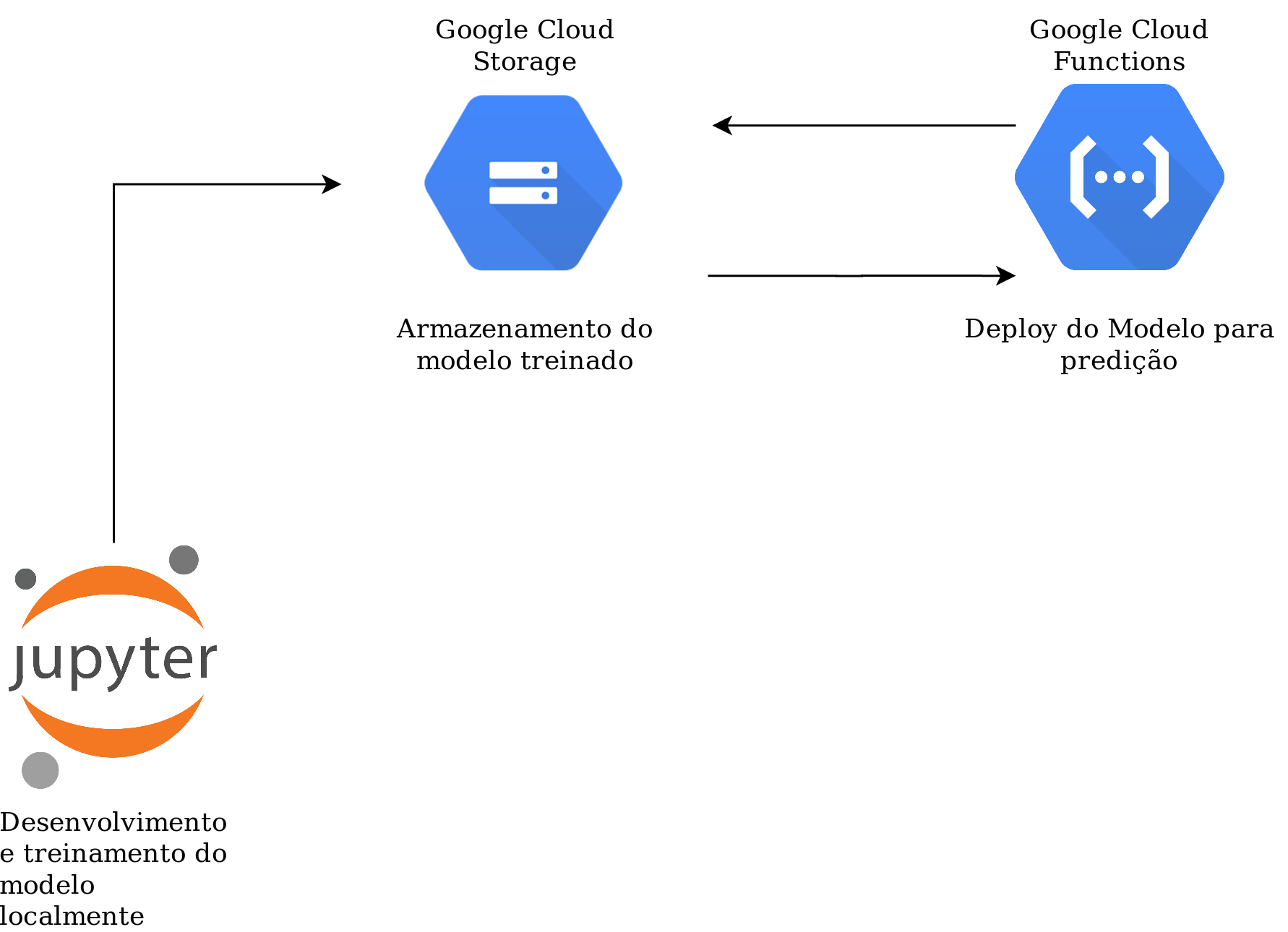
Etapas para Desenvolvimento:
1 - EDA Básico com Pandas Profiling;
2 - Desenvolvimento e treinamento do modelo utilizando Scikit-Learn e Pandas;
3 - Upload do modelo salvo para um bucket no Google Cloud Storage;
4 - Desenvolvimento da API Flask para deploy no Google Cloud Function.
EDA Básico
Para criar nosso modelo de predição, vamos utilizar um dataset disponível no Kaggle com features de imóveis de algumas cidades brasileiras. Pelo o que pude perceber do dataset, o autor fez o scrapping das páginas do Quinto Andar para conseguir essas informações.
A primeira etapa de todo projeto de data science é fazer um EDA (Exploratory Data Analysis) do dataset com o qual se vai trabalhar. Muitas vezes esse tipo de análise é bem demorada, pois exige muita atenção. Por isso, hoje vamos utilizar uma ferramenta MUITO útil nessas análises iniciais o Pandas Profiling. Essa lib do Python gera um report bem detalhado sobre o dataset no qual é aplicada, ela nos ajuda a economizar bastante tempo.
A instalação da lib é bem simples em ambientes virtuais:
pip install pandas-profiling[notebook]
import pandas as pd
from pandas_profiling import ProfileReport
#Carregando o dataset
path_data = 'caminho_para_dataset'
df_rent = pd.read_csv(path_data)
df_rent.head()
O dataset conta com as seguintes features:
- city: cidade em que o imóvel se encontra;
- area: área total do imóvel (m2);
- rooms: quantidade de quartos do imóvel;
- bathroom: quantidade de banheiros;
- parking spaces: vagas de estacionamento;
- floor: andar do imóvel;
- furniture: se o imóvel é mobilhado;
- hoa (R\$): valor do condomínio;
- rent amount (R\$): valor do alguel;
- property tax (R\$): IPTU;
- fire insurance (R\$): seguro contra incêndio;
- total (R\$): valor total do imóvel
A coluna total (R\$) trata do somatário dos valores de condomínio, aluguel, IPTU e seguro contra incêndio. Como queremos predizer apenas o valor de aluguel (rent amount (R\\$)), então, a coluna de total irá enviesar a análise. Por isso vamos excluí-la.
#O total amount pode ser descartado completamente dessa análise
df_train = df_rent.drop(columns=['total (R$)'])
df_train.head()
profile = ProfileReport(df_rent, title='Pandas Profiling Report', html={'style':{'full_width':True}})
profile
Identificação de Anomalias
Vamos procurar alugueis muito mais caros que o normal, a regra será: Q3 + 3,5xIQR.
Como Pandas Profiling nos acusou, nosso Q3 = 5000 e nosso IQR = 3750
Q3 = 5000
IQR = 3750
df_train[df_train['rent amount (R$)'] >= Q3 + 3.5*IQR]
Bom, a maioria dos aluguéis absurdos estão em São Paulo (nenhuma novidade aí). Temos alguns valores que chegam a 45k/mês, porém, a área do imóvel é de 700 metros quadrados, 7 banheiros, 4 quartos e 8 vagas de estacionamento. Então, creio que esteja condizente. Como não temos informações relativas ao bairro do imóvel este tipo de análise fica um pouco complicada.
Porém, temos uma situação (id 2859) em que temos o aluguel e o valor de condomínio em 20k/mês, muito provavelmente é um erro. Vamos eliminar essa linha.
df_train = df_train.drop(2859)
Tratamento de Missing Values
Na coluna de floor algumas linhas que não possuem valor foram tratadas como '-', vamos substituir esses valores.
#Substituindo os valores de '-' na coluna floor
df_train = df_train.replace('-', 0)
Separação de Dados
X = df_train.drop(columns=['rent amount (R$)'])
y = df_train['rent amount (R$)']
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.15)
x_train
Construção do Modelo
Como vamos fazer o deploy do modelo como um único main method no Google Cloud Functions não é interessante para nós criarmos mais funções para tratamento de entradas do modelo. Para fazer esse pré processamento vamos utilizar algumas funções bem interessantes da biblioteca Scikit-Learn. A estratégia aqui é criar uma única pipeline que engloba tanto o modelo de regressão quanto as funções de pré processamento. Dessa forma podemos gerar tudo em um único arquivo .pkl, garantindo que toda a pipeline seja rodada da mesma forma, tanto para treinamento quanto para predição.
O nosso dataset é constituído tanto de dados numéricos quanto de dados categóricos, então, vamos construir duas pipelines diferentes e junta-las em uma única ao final. A primeira vai tratar os dados numéricos e a segunda os categóricos.
Para a pipeline numérica vamos apenas substituir os valores faltantes (nenhum até agora) pela mediana de todos os outros valores. Em seguida, vamos padronizar os inputs através do StandardScaler.
Já na pipeline categórica, vamos substituir os valores faltantes por uma string "missing_values" e em seguida vamos fazer o Hot Enconding das variáveis.
Para criar uma única função de pré processamento, vamos juntar as duas pipelines utilizando a função ColumnTransformer do Sklearn. Ela é útil para ser utlizada em datasets heterogêneos, ou seja, com dados categóricos e numéricos. Com essa função podemos agregar diferentes tipos de pipelines de pré processamento.
Por fim, criaremos a pipeline final com as funções de pré processamento e com o regressor.
#truque para facilitar nossa vida
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LinearRegression
#Pipeline para dados numéricos
numeric_features = ['area', 'rooms', 'bathroom', 'parking spaces', 'floor', 'hoa (R$)', 'property tax (R$)', 'fire insurance (R$)']
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')), #Usando a mediana para valores missing
('scaler', StandardScaler())]) #Padronizando os inputs
#Pipeline categórica
categorical_features = ['city', 'animal', 'furniture']
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
#Agregando as duas pipelines
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
#Pipeline final
clf = Pipeline(steps=[('preprocessor', preprocessor),
('regressor', LinearRegression())])
clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)
from sklearn.metrics import mean_squared_error
import numpy as np
rmse = np.sqrt(mean_squared_error(y_test.values, y_pred))
print('O RMSE é:', rmse)
Conseguimos um RMSE um pouco alto, mas como nosso foco não é a otimização do modelo em si, vamos deixar assim mesmo. Com ele pronto já podemos fazer os testes com o Google Cloud Functions.
Persistindo o Modelo
Antes de enviar o modelo para o Google Cloud Storage, devemos salvar o modelo localmente. Para isso vamos utilizar uma lib chamada joblib.
import joblib
model_path = './modelos'
joblib.dump(clf, 'modelos/rent_pred.pkl')
loaded = joblib.load('modelos/rent_pred.pkl')
loaded.predict(x_test)
Configurações para Uso do Google Services
Para iniciar esta etapa, a primeira coisa a ser feita é criar um projeto no Google Cloud Platform. O Google oferece 300 dólares gratuitos para quem estiver começando a utilizar seus serviços, é uma boa ajuda para quem gosta de fazer PoCs com novas tecnologias.
Em seguida, devemos instalar o Google Cloud command line tools e depois setar nossas credenciais para conexão com as aplicações necessárias. A instalação do command lines tools pode ser feita assim (em máquinas linux, se você usa windows só posso lamentar):
curl -O https://dl.google.com/dl/cloudsdk/channels/
rapid/downloads/google-cloud-sdk-255.0.0-linux-x86_64.tar.gz
tar zxvf google-cloud-sdk-255.0.0-linux-x86_64.tar.gz
google-cloud-sdk
./google-cloud-sdk/install.sh
Suas credenciais devem ser ajustadas assim:
gcloud config set project projeto_que_voce_criou
gcloud auth login
gcloud init
gcloud iam service-accounts create nome_conta_de_serviço
gcloud projects add-iam-policy-binding id_do_seu_projeto
--member "serviceAccount:nome_conta_de_serviço@id_do_seu_projeto.iam.gserviceaccount.com" --role "roles/owner"
gcloud iam service-accounts keys create nome_conta_de_serviço.json --iam-account
nome_conta_de_serviço@id_do_seu_projeto.iam.gserviceaccount.com
export GOOGLE_APPLICATION_CREDENTIALS=/caminho/credenciais/nome_conta_de_serviço.json
Para enviarmos o modelo para o GCS devemos instalar a lib do google cloud para python, isso pode ser feito assim:
pip install --user google-cloud-storage
#Ajustando credenciais
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]="/caminho/credenciais/nome_conta_de_serviço.json"
Após as configurações, o primeiro passo a ser tomado é criar um bucket no GCS para armazenar nosso modelo, isso é feito da seguinte maneira:
from google.cloud import storage
bucket_name='hype_storage'
storage_client = storage.Client()
storage_client.create_bucket(bucket_name)
for bucket in storage_client.list_buckets():
print(bucket.name)
Agora vamos salvar o nosso modelo no bucket que acabamos de criar.
#Fazendo o upload do modelo para o seu bucket no gcp
from google.cloud import storage
bucket_name = "hype_storage"
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blob = bucket.blob("modelos/")
blob.upload_from_filename("./modelos/rent_pred.pkl")
Para confirmar que o modelo foi salvo corretamente no bucket, vamos fazer um teste localmente.
#Pegando o modelo do bucket
from google.cloud import storage
bucket_name = "hype_storage"
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blob = bucket.blob('modelos/')
blob.download_to_filename('modelos/rent_pred_gcs2.pkl')
gcs_model = joblib.load('modelos/rent_pred_gcs2.pkl')
gcs_model.predict(x_test)
x_test
Ok, tudo funcionando normalmente.
- Configuramos o Google Cloud command line;
- Ajustamos nossas credenciais;
- Criamos o bucket no GCS;
- Enviamos o modelo;
Agora, só nos resta fazer o deploy final para o Google Cloud Functions.
Criando as Funções no Google Cloud Functions
Como falei anteriormente, para fazermos o deploy do nosso modelo utilizando FaaS, nós precisamos apenas ajustar uma função (literalmente).
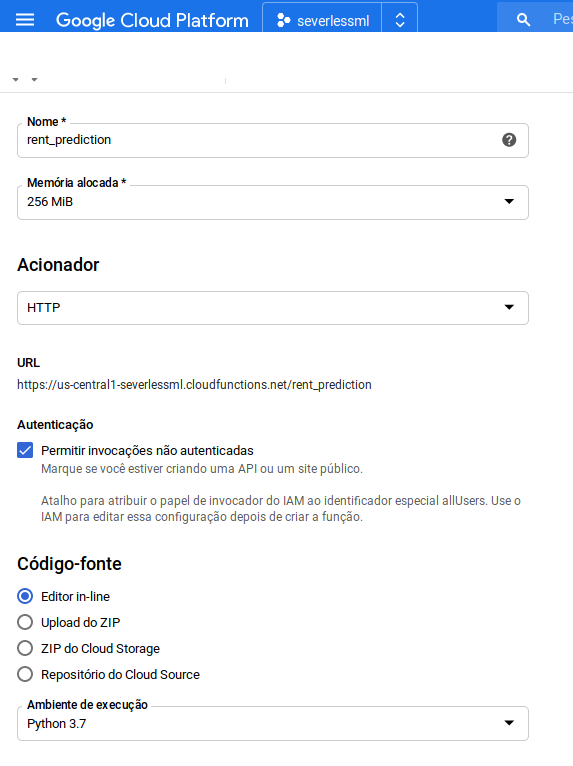
Para a criação de uma função Cloud Function no Google, siga os seguinte passos:
- Procure por "Cloud Function" na barra lateral;
- Clique em "Criar Função";
- Adicione o nome que desejar para a função;
- Para teste, clique em "Permitir invocações não autenticadas";
- Selecione Python 3.7 como Ambiente de execução.
A nossa função no GCF funciona basicamente como um aplicativo Flask. Ela vai receber um request, processar e gerar um resultado. Bom, nosso request será um json contendo as infomações do imóvel que queremos prever o aluguel e o nosso resultado será o valor predito do aluguel.
Quando a função for criada, você perceberá dois arquivos editáveis na plataforma. No MAIN.PY nós iremos criar nossa função para predição e no REQUIREMENTS.TXT iremos colocar as libs a serem instaladas.
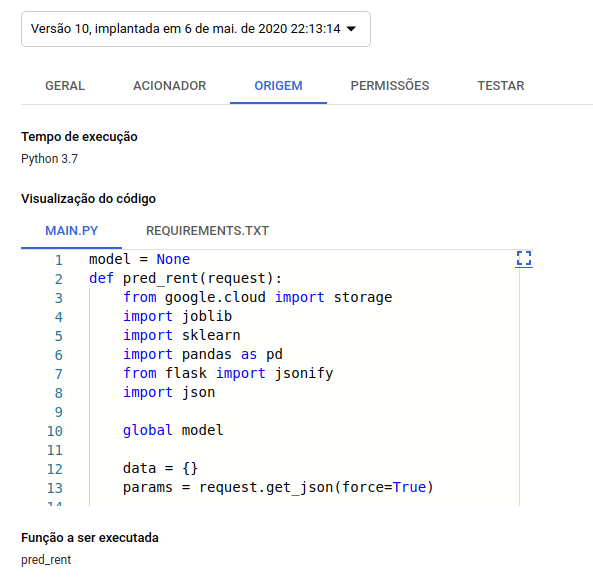
O código da nossa função main.py é o seguinte:
model = None
def pred_rent(request):
from google.cloud import storage
import joblib
import sklearn
import pandas as pd
from flask import jsonify
import json
global model
data = {}
params = request.get_json(force=True)
request_pd = pd.DataFrame.from_dict(params, orient='index').transpose()
if not model:
# #Configurando bucket
bucket_name = 'hype_storage'
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
#download do modelo
blob = bucket.blob('modelos/')
blob.download_to_filename('/tmp/rent_pred.pkl')
model = joblib.load('/tmp/rent_pred.pkl')
data['valor aluguel'] = str(model.predict(request_pd)[0])
return jsonify(data)
Com o Google Cloud Funtions não podemos criar pastar e salvar arquivos normalmente, mas podemos salvar arquivos na pasta /tmp. Por essa razão salvamos nosso modelo nela após pegarmos do bucket.
Também usamos uma variável global no nosso modelo para não termos a necessidade de leitura de arquivo do HD a cada requisição da API, isso agiliza muito o processo de inferência.
Nosso requirements.txt ficará das seguinte forma:
# Function dependencies, for example:
# package>=version
google-cloud-storage
sklearn
pandas
flask
Pronto, tudo configurado. Só nos resta testar. O GCF nos fornece uma área de testes da função.
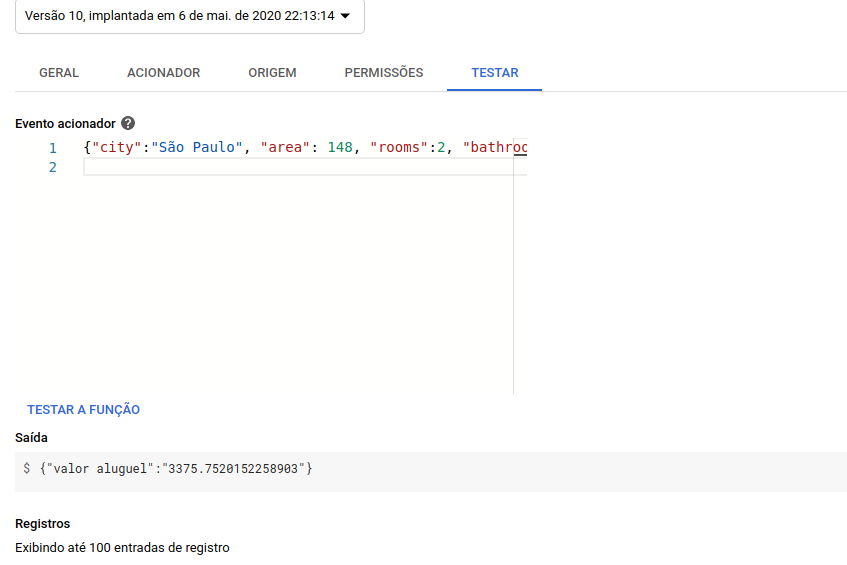
Vamos criar um JSON de exemplo e ver se nosso modelo nos retorna algo. O JSON para teste pode ser o seguinte:
request_example = {"city":"São Paulo", "area": 148, "rooms":2, "bathroom":1, "parking spaces": 1,
"floor": 1, "animal": "accept", "furniture": "furnished", "hoa (R$)": 950,
"property tax (R$)": 60, "fire insurance (R$)": 45}
Isso nos gera o seguinte resultado:
Também podemos fazer o teste enviando uma requisição diretamente para a URI gerado pela função:
import requests
result = requests.post("https://us-central1-severlessml.cloudfunctions.net/teste3", json={"city":"Belo Horizonte", "area": 85, "rooms":2, "bathroom":1, "parking spaces": 1, "floor": 1, "animal": "accept", "furniture": "furnished", "hoa (R$)": 150, "property tax (R$)": 60, "fire insurance (R$)": 45})
result
result.json()
Conclusões
Apesar dessa PoC ter sido bem pequena e simples, consegui simular uma pipeline de um modelo do treinamento ao deploy em um ambiente serverless. A parte mais interessante sem dúvida foi aprender coisas novas sobre as ferramentas do Google Cloud Platform.
As principais conclusões que tirei desse mini projeto foram:
- A facilidade de trabalho no ambiente Cloud da Google é espantosa. A curva de aprendizado é muito boa;
- As integrações entre serviços são bem fáceis também;
- O deploy de um modelo como FaaS foi bem simples, mas como foi um modelo básico e tudo integrado em uma única pipeline acho que essa opinião pode estar um pouco enviesada;
- Apesar de toda essa facilidade, me pergunto se, com o dólar a quase 6 reais, essa pipelines são viáveis para empresas de médio e pequeno porte. Já que você é cobrado por requisição;
- Não pude testar a questão da escalabilidade do modelo, como eu disse, o dólar ta em quase 6 reais.
TODOs:
- Utilizar modelos de Tensorflow ou Pytorch para testar com modelos mais complexos;
- Utilizar múltiplas funções;
- Criar pipelines mais complexas para teste.